
Large Language Models from leading AI providers have transformed what is possible with AI-driven applications. Their ability to generate human-like text, reason across complex inputs, and engage in nuanced conversation has created a generation of AI tools that were not conceivable five years ago.
But they share a fundamental limitation that matters significantly in enterprise contexts: their knowledge is fixed at the point of training.
A model trained on data up to a certain date cannot know what happened after that date. It cannot access your organisation's internal documents, policies, or proprietary data. And when it encounters questions that fall outside its training distribution, it will sometimes generate responses that are confident, coherent, and wrong.
For enterprise applications where accuracy, recency, and domain specificity are non-negotiable such as compliance, procurement, financial analysis, customer service, field operations this limitation is not acceptable.
Retrieval-Augmented Generation (RAG) is the architectural approach that addresses it.
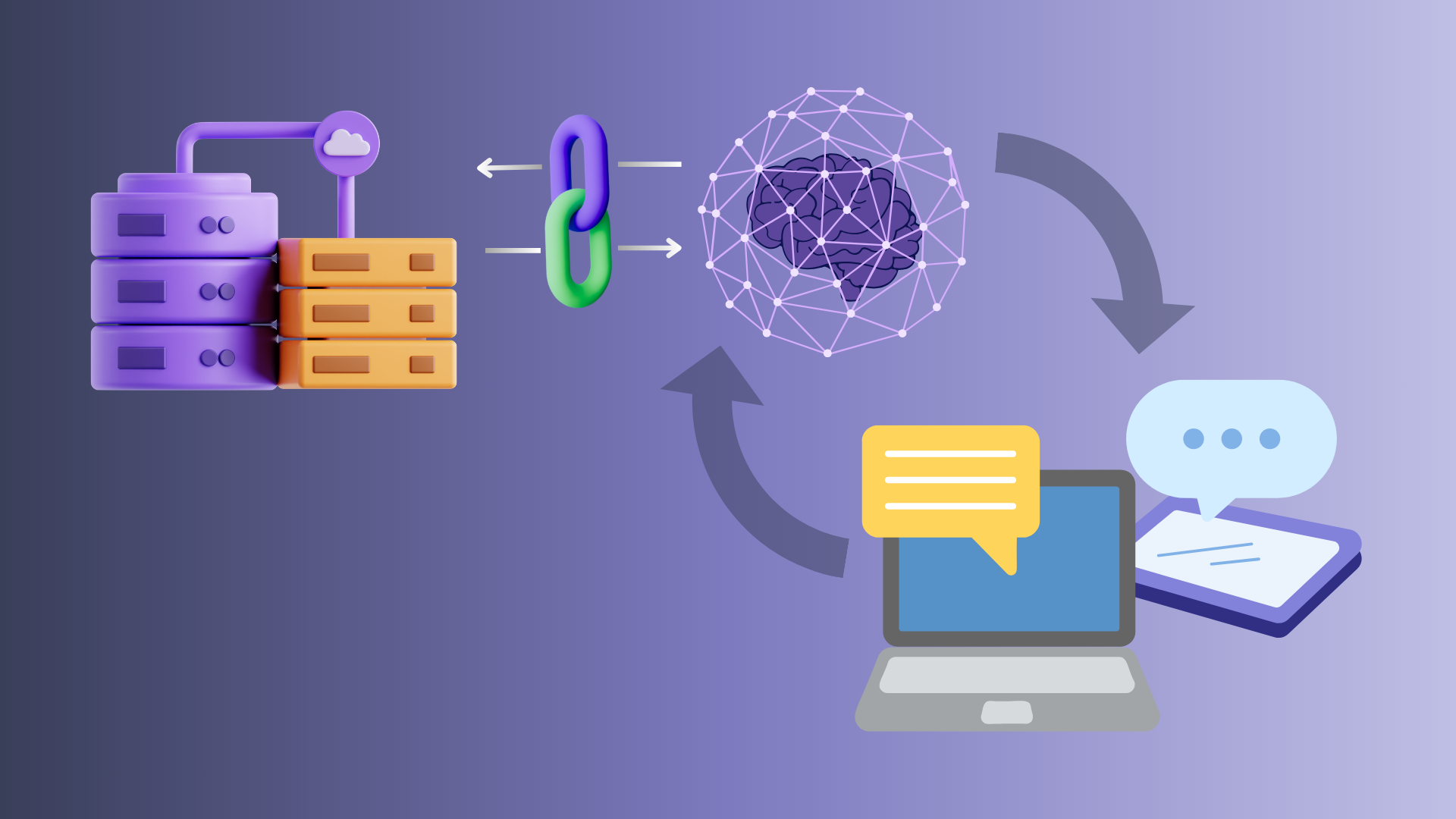
What RAG Is and How It Works
RAG is a hybrid AI framework that enhances language models by integrating external information retrieval into the generation process. Rather than relying solely on pre-trained knowledge, a RAG system first retrieves relevant information from external sources — enterprise databases, document repositories, live APIs, knowledge bases — and then provides that retrieved information to the language model as context for generating its response.
The result is an AI system that combines the language capability of a large model with the knowledge currency and specificity of your enterprise's own data.
The process in two stages:
Stage 1: Retrieval When a user submits a query, the system converts it into a vector embedding and searches the enterprise knowledge base for the most semantically similar documents or records. This retrieval is powered by vector databases and semantic search, ensuring that what is retrieved is contextually relevant not just keyword-matched.
Stage 2: Generation The retrieved documents are passed to the language model alongside the original query as additional context. The model generates a response that draws on both its trained capabilities and the specific, current information retrieved from the enterprise knowledge base.
A Concrete Enterprise Example
User query: "What are our current payment terms for Tier 2 suppliers in the automotive category?"
Without RAG: The language model generates a plausible-sounding response based on general knowledge of supplier payment terms — which may or may not reflect your organisation's actual policies.
With RAG: The system retrieves the relevant section of your procurement policy document, the most recent supplier agreement template, and any recent updates communicated by the finance team and generates a response grounded in those specific documents, with the source traceable.
The difference is not just accuracy. It is auditability. The ability to trace every AI response back to a specific source, which is increasingly required for compliance and governance in regulated industries.
The Five Components of a RAG System
Retriever: Searches and fetches relevant content from external sources such as enterprise document repositories, databases, search indexes, or live APIs. The quality of the retriever directly determines the quality of the generation that follows.
Embedding Model: Converts both the user query and the stored documents into vector representations, enabling semantic similarity matching rather than keyword matching. The embedding model is what allows the retriever to find documents that are relevant in meaning rather than just in terminology.
Vector Database: Stores the indexed embeddings of enterprise knowledge and enables fast, scalable similarity search at query time. As covered in the Vector Databases guide, this is the retrieval infrastructure that makes RAG performant at enterprise scale.
Ranking Mechanism: Evaluates the retrieved documents and determines which are most relevant to pass to the generation stage. This prevents the language model from being flooded with marginally relevant content that could dilute or distort the response.
Generator: The language model that takes the retrieved context and the original query and produces the final response. The generator's role in a RAG system is more constrained and more reliable than in a standalone LLM — it is reasoning over specific provided context rather than drawing on general training data.
Why RAG Outperforms Standalone LLMs for Enterprise Use Cases
Standalone LLM | RAG-Enhanced LLM | |
|---|---|---|
Knowledge currency | Fixed at training cutoff | Real-time via retrieval |
Domain specificity | General training data | Enterprise knowledge base |
Hallucination risk | Higher — generates from training | Lower — grounded in retrieved facts |
Auditability | Limited | Response traceable to source |
Retraining cost | High — requires full retraining for updates | Low — update the knowledge base |
Enterprise Applications Where RAG Creates the Most Value
Enterprise Knowledge Management: Employees query internal policies, project documentation, and historical records through a RAG-powered assistant that retrieves from live enterprise knowledge rather than generating from outdated training data. A legal team retrieves relevant contract precedents. A procurement manager retrieves current supplier terms. An engineer retrieves the latest product specification. All from a single interface, with responses grounded in current enterprise documents.
Compliance and Regulatory Workflows: Compliance teams in financial services, manufacturing, and other regulated industries use RAG-powered assistants to retrieve and interpret the latest regulatory guidance, internal policy documents, and audit requirements — with responses traceable to source documents for audit purposes.
Customer and Dealer Service Operations: Service agents and dealer support teams use RAG-powered tools to retrieve accurate, current product information, warranty terms, and resolution procedures generating responses from live enterprise knowledge rather than generic training data that may not reflect current product configurations or policy updates.
Financial Analysis and Market Intelligence: Finance teams and analysts retrieve the latest market data, regulatory updates, and internal financial reports through AI assistants that combine retrieval from live sources with the synthesis capability of a language model.
Implementation Challenges and How to Address Them
Retrieval relevance: The most common failure mode in RAG implementations is retrieving documents that are related but not precisely relevant — flooding the language model with context that dilutes rather than improves the response. The mitigation is investing in retrieval quality: chunking strategies, embedding model selection, and ranking mechanisms that prioritise precision over recall.
Latency: Adding a retrieval step introduces latency compared to a direct LLM query. The mitigation is infrastructure optimisation — caching frequently retrieved content, using appropriately sized vector indexes, and designing retrieval pipelines for the response time requirements of the specific application.
Security and access control: Enterprise knowledge bases contain documents with varying sensitivity levels. A RAG system must enforce access controls at the retrieval layer ensuring that users only retrieve documents they are authorised to access, and that agents operating within governed platforms retrieve within defined permission boundaries.
Knowledge base quality: RAG is only as good as the knowledge it retrieves from. Outdated, inconsistent, or poorly structured enterprise documentation produces unreliable retrieval and unreliable generation. Treating the enterprise knowledge base as a maintained, governed asset — rather than a static document dump — is a prerequisite for production-grade RAG performance.
RAG and Agentic AI
As enterprises move toward agentic AI systems — where agents execute multi-step workflows autonomously — RAG becomes the mechanism through which agents access business context in real time.
An agent handling a procurement decision retrieves the relevant policy, the supplier's performance history, and the current budget position before reasoning about the recommendation. An agent managing a service escalation retrieves the product manual, the warranty terms, and the customer's service history before determining the resolution path.
The Context Manager within Vishleshan's Vidura platform is built on this principle — providing agents with the contextually relevant business information they need to make governed, accurate decisions at runtime, through a retrieval architecture that scales across enterprise knowledge sources.
RAG is the architectural bridge between what language models are capable of and what enterprise AI applications actually require. It combines the language and reasoning capability of large models with the knowledge currency, domain specificity, and auditability that enterprise deployment demands.
For organisations deploying conversational AI, knowledge management tools, compliance automation, or agentic workflows, RAG is not an optional enhancement. It is the difference between an AI that performs reliably in production and one that performs impressively in a demo.
Vishleshan builds enterprise AI solutions powered by RAG architectures enabling accurate, grounded, auditable AI across knowledge management, service operations, and agentic workflows. Book a Demo.